Техническое задание
Бэкенд сервиса поиска пропавших людей
Цель
Разработать учебный прототип (MVP) системы поиска пропавших людей, включающей управление волонтёрами, учёт инцидентов, трекинг координат и уведомления.
Проект должен включать в себя:
- версионированый REST AРІ для взаимодействия с микросервисами
- асинхронное взаимодействие через Kafka
- реализацию паттерна transactional outbox (либо с помощью Kafka Connect и Debezium Postges Connector, либо с помощью механизма планировщиков Spring Boot)
- аутентификацию и авторизацию через Кеycloak
- мониторинг, логирование и наблюдаемость с помощью механизмов Grafana Loki (аггрегация логов), Grafana Tempo (распределенная трассировка), Prometheus (сбор метрик) и Grafana (визуализация данных)
- развертывание микросервисов либо в Kubernetes, либо в Docker с помощью Docker Compose
- развертывание инфраструктурных компонентов либо в Kubernetes, либо в Docker с помощью Docker Compose
- реализацию паттернов Retry, Rate Limit, Circuit Breaker
- реализацию единой точки входа в приложение с помощью Spring Cloud Gateway Server
1. Аутентификация и авторизация
Система должна обеспечивать доступ к эндпоинтам на основе двух ролей:
ROLE_VOLUNTEER- зарегистрированный волонтерROLE_ADMIN- администратор системы
Все запросы к защищенным эндпоинтам извне системы должны проходить через Gateway Server и содержать токен доступа в формате ЈWT. На основе роли из токена принимается решение о предоставлении доступа к тому или иному эндпоинту.
Предлагаемый сценарий первичной регистрации волонтера
- Пользователь открывает начальную страницу сайта.
- У пользователя нет сессионной куки, соответственно система его не узнает.
- Пользователю доступен UI входа или регистрации.
- Пользователь нажимает кнопку "Стать волонтером".
- Система редиректит пользователя на UI Keycloak.
- Пользователь регистрируется в Identity Provider, заполняя ФИО, логин, пароль, email.
- Identity Provider редиректит пользователя по адресу логина системы с кодом авторизации.
- Система меняет код авторизации на токены доступа и идентификации.
- Система создает сессионную куку.
- Пользователю доступны эндпоинты согласно роли
ROLE_VOLUNTEERиз Токена доступа. - Пользователю показывается экран с формой заполнения контактной информации о себе:
- 1. ФИО
- 2. Пол
- 3. Номер телефона
- 4. email
- 5. Дата рождения
- 6. Населенный пункт проживания (название)
- 7. Район населенного пункта проживания (необязательное поле).
- Пользователь заполняет форму и отправляет запрос на регистрацию.
- Система по куке получает токен доступа из хранилища и передает его далее по цепочке.
- Система проверяет наличие и валидность токена доступа в запросе к эндпоинту и соответствие роли.
- Система проверяет корректность переданых данных.
- Система сохраняет данные пользователя, при этом в качестве поля
user_idиспользуетсяsub(идентификатор, назначенный пользователю в Identity Provider) из токена доступа. - Система возвращает суррогатный, сгенерированный системой идентификатор записи в БД для зарегистрированного волонтера и ФИО волонтера.
Сценарий повторного входа по куке (после того, как пользователь ввел все регистрационные данные)
- Пользователь открывает начальную страницу сайта.
- У пользователя есть сессионная кука.
- Система по куке получает токен доступа и передает его далее по цепочке.
- Система проверяет наличие и валидность токена доступа в запросе к эндпоинту и соответствие роли.
- Система распознает пользователя как зарегистрированного в системе волонтера (по
subиз токена доступа). - Система возвращает суррогатный, сгенерированный системой идентификатор записи в БД для зарегистрированного волонтера и ФИО волонтера.
- Система показывает пользователю UI волонтера.
Сценарий повторного входа по куке (пользователь зарегистрировался в Keycloak, но не ввел данные регистрации в системе)
- Пользователь открывает начальную страницу сайта.
- У пользователя есть сессионная кука.
- Система по куке получает токен доступа и передает его далее по цепочке.
- Система проверяет наличие и валидность токена доступа в запросе к эндпоинту и соответствие роли.
- Система НЕ распознает пользователя как зарегистрированного в системе волонтера (по
subиз токена доступа не найден зарегистрированный пользователь). - Система возвращает ответ о том, что пользователь не найден.
- Система показывает пользователю UI регистрации.
Сценарий повторного входа без куки (после того, как пользователь ввел все регистрационные данные)
- Пользователь открывает начальную страницу сайта.
- У пользователя нет сессионной куки.
- Пользователю доступен UI входа и регистрации.
- Пользователь нажимает кнопку "Войти"
- Пользователь вводит логин и пароль в UI Keycloak.
- Происходит обмен кода авторизации на токены доступа и идентификации, создание сессионной куки и сохранение токенов в хранилище.
- Система по куке получает токен доступа и передает его далее по цепочке.
- Система проверяет наличие и валидность токена доступа в запросе к эндпоинту и соответствие роли.
- Система распознает пользователя (по
subиз токена доступа). - Система возвращает суррогатный, сгенерированный системой идентификатор записи в БД для зарегистрированного волонтера и ФИО волонтера.
- Пользователю доступен UI волонтера.
Сценарий повторного входа без куки (пользователь зарегистрировался в Keycloak, но не ввел данные регистрации в системе)
- Пользователь открывает начальную страницу сайта.
- У пользователя нет сессионной куки.
- Пользователю доступен UI входа и регистрации.
- Пользователь нажимает кнопку "Войти"
- Пользователь вводит логин и пароль в UI Keycloak.
- Происходит обмен кода авторизации на токены доступа и идентификации, создание сессионной куки и сохранение токенов в хранилище.
- Система по куке получает токен доступа и передает его далее по цепочке.
- Система проверяет наличие и валидность токена доступа в запросе к эндпоинту и соответствие роли.
- Система НЕ распознает пользователя (по
subиз токена доступа). - Система возвращает ответ о том, что пользователь не найден.
- Пользователю доступен UI регистрации.
Аутентификация администраторов аналогична аутентификации волонтеров, за исключением того, что регистрация в Identity Provider осуществляется вручную. В данном задании реализовывать функционал управления администраторами системы не требуется.
2. Управление волонтерами в системе поиска (Volunteer Service)
-
Волонтер должен иметь возможность зарегистрироваться в системе:
POST /api/v1/volunteer/register/me-
В теле запроса передается:
- ФИО
- Пол
- Номер телефона
- Дата рождения
- Населенный пункт проживания (название)
- Район населенного пункта проживания (необязательное поле).
-
Волонтер должен иметь возможность посмотреть данные о своей регистрации
GET /api/v1/volunteer/me
-
Волонтер должен иметь возможность удалить свою учетную запись из системы поиска пропавших людей
DELETE /api/v1/volunteer/me
-
Волонтер должен иметь возможность обновить данные о себе в системе поиска пропавших людей:
PATCH /api/v1/volunteer/me- Населенный пункт
- Район населенного пункта
- Фамилия
- контактный номер телефона
-
Администраторы системы должны иметь возможность получить список зарегистрированных волонтеров, используя следующие фильтры:
POST /api/v1/admin/volunteer/list- Населенный пункт
- Район населенного пункта
- Статус волонтера (свободен, на задании).
-
Администраторы системы должны иметь возможность посмотреть данные любого волонтера
GET /api/v1/admin/volunteer/{id}
-
Система должна предоставлять возможность получить контактные данные волонтеров по списку идентификаторов волонтеров.
POST /internal/api/v1/volunteer/list- В теле запроса передается список идентификторов волонтеров
- Эндпоинт не выставлен наружу через Gateway Server, доступен только внутри системы.
-
Волонтер должен иметь возможность подтвердить свое участие в инциденте:
POST /api/v1/volunteer/me/incident/act- В теле запросе передается идентификатор инцидента и действие (отказ / подтверждение).
-
Поведение системы при получении подтверждения / отказа:
-
Подтверждение:
- Волонтер может принимать участие только в одном инциденте. Остальные запросы отклоняются со статусом 409.
- Если проверка на шаге 1 успешна, отправить сообщение в топик kafka
volunteer_incident_assign_event_v1- идентификатор инцидента
incident_id - идентификатор волонтера
volunteer_id(берется из БД поsubиз токена доступа) - статус
ACCEPT
- идентификатор инцидента
-
Отказ:
- Если пришел статус
REJECTи волонтер уже работает над этим инцидентом, то он прекращает работу над инцидентом. - В любом случае необходимо отправить сообщение в топик kafka
volunteer_incident_assign_event_v1- идентификатор инцидента
incident_id - идентификатор волонтера
volunteer_id - статус
REJECT
- идентификатор инцидента
- Если пришел статус
-
Подтверждение:
IncidentAssignEventV1
{
"type": "record",
"name": "VolunteerIncidentAssignEventV1",
"namespace": "ru.cloudjava.rescue.volunteer.avro",
"doc": "Решение волонтёра об участии в инциденте",
"fields": [
{ "name": "event_id", "type": { "type": "string", "logicalType": "uuid" } },
{ "name": "occurred_at", "type": { "type": "long", "logicalType": "timestamp-millis" } },
{ "name": "producer", "type": "string" },
{ "name": "incident_id", "type": { "type": "string", "logicalType": "uuid" } },
{ "name": "volunteer_id", "type": { "type": "string", "logicalType": "uuid" } },
{ "name": "status", "type": { "type": "enum", "name": "AssignDecision", "symbols": ["ACCEPT", "REJECT"] } }
]
}X-USER-ID, подставляя в качестве значения sub из токена доступа.
Примерная модель данных:
Volunteer:
idUUID primary keyuser_idtext not null unique (subизaccess_token, сгенерированный Кеycloak)first_nametext not nulllast_nametext not nullmiddle_nametextstatustext not null (FREE,ASSIGNED_TASK) defaultFREEcreate_datetimestamptz not null default nowupdate_datetimestamptzlocation_idreferences location(id)current_incident_idUUID
Location:
idUUID primary keynametext not null uniqueparent_loc_idUUID references location(id)create_datetimestamptz not null default nowlocation_kindtext not null default 'PARENT' ('CHILD')update_datetimestamptz
Contactinfo:
idUUID primary keycontacttext not null uniquecontact_typetext not null (enumPHONE,EMAIL)create_datetimestamptz not null default nowupdate_datetimestamptzvolunteer_idUUID references volunteer (id)
3. Управление местонахождением волонтеров (Tracking Service)
-
Система должна принимать, хранить и обновлять данные о местонахождении волонтера по его идентификатору. Эндпоинт доступен для
ROLE_VOLUNTEER.POST /api/v1/tracking- В запросе передается идентификатор волонтера, текущие координаты
latширота,lonдолгота -
Поведение системы:
- Сохранение или обновление записи в БД
- Отправка сообщения в топик Кафка
volunteer_location_change_event_v1. (Ученикам предлагается подумать над различными настройками Kafka Producer и вариантами отправки сообщения: синхронный, асинхронный, с помощью паттерна Transactional Outbox, взвесить все "за" и "против" и выбрать один из вариантов, обосновав свое решение в JavaDoc)
-
Система должна выдавать список идентификаторов волонтеров и их координат в пределах указанных координат. Эндпоинт доступен для роли
ROLE_ADMIN.POST /api/v1/tracking/rectanglelat_1,lon_1,lat_2,lon_2, представляющих собой координаты левой верхней и правой нижней границ прямоугольника- Если количество координат в прямоугольнике превышает заданный в конфигурации параметр (
600), то тогда возвращается ответ в виде кластеров координат, с количеством координат в одном кластере. Количество кластеров также ограничено конфигурационным параметром сервера (800). Для реализации функционала рекомендуется использовать функции Postgis:ST_Transform,ST_ClusterDBSCAN,ST_Centroid,ST_Collect,ST_Y,ST_X,ST_Intersects - Если координаты волонтера не обновлялись в течение конфигурируемого времени (10 дней), то они не попадают в список.
- При расчете кластеров все расстояния должны быть в метрах. Необходимо рассчитать параметр
epsфункцииST_ClusterDBSCANв зависимости от размера прямоугольника, в котором запрашиваются координаты волонтеров. Чем больше прямоугольник, тем больше параметрeps. Также требуется учесть, что в некоторых регионах может быть совсем мало волонтеров, поэтому параметрminpointsданной функции должен быть равен единице, то есть один волонтер может составить кластер, если поблизости от него нет других волонтеров в пределахepsметров. - Для более точного понимания того, что требуется реализовать, рекомендуется внимательно изучить тесты
tracking-service.
-
Система должна предоставлять текущие координаты волонтера по его идентификатору. Эндпоинт доступен для роли
ROLE_VOLUNTEERиROLE_ADMIN.GET /api/v1/tracking/volunteer/{id}
-
Система должна предоставлять возможность получить список ближайших к указанной координате (
lat,lon) N волонтеров и их координат. Эндпоинт доступен для ролиROLE_ADMIN, если запрос приходит извне приложения и доступен для всех сервисов самого приложения.POST /api/v1/tracking/nearest- В запросе передается:
- количество записей, которые необходимо найти (
number) - координаты геолокации
lat,lon
- количество записей, которые необходимо найти (
- В ответе список идентификаторов волонтеров и их координат
-
Система должна предоставлять список координат волонтеров по списку идентификаторов волонтеров, если для идентификатора волонтера из списка не найдены координаты, то
возвращаются
пустые значения. Эндпоинт доступен для роли
ROLE_ADMIN.POST /api/v1/tracking/volunteer/list- В запросе передается список идентификаторов волонтеров, координаты которых необходимо найти
- В ответе передается список идентификаторов волонтеров и их координат, если координаты не найдены, то возвращается только идентификатор волонтера
Примерная модель данных
Volunteer Track:
idUUID primary keylatdouble precision not nulllondouble precision not nullcoordinatesgeography (Point, 4326) not null (PostGis)create_datetimestamptz not null default nowupdate_datetimestamptzvolunteer_idUUID not null unique
VolunteerLocationChangeEventV1:
{
"type": "record",
"name": "VolunteerLocationChangeEventV1",
"namespace": "ru.cloudjava.rescue.location.avro",
"doc": "Событие изменения геопозиции волонтера",
"fields": [
{ "name": "event_id", "type": { "type": "string", "logicalType": "uuid" } },
{ "name": "occurred_at", "type": { "type": "long", "logicalType": "timestamp-millis" } },
{ "name": "producer", "type": "string" },
{ "name": "volunteer_id", "type": { "type": "string", "logicalType": "uuid" } },
{ "name": "lat", "type": "double" },
{ "name": "lon", "type": "double" }
]
}
4. Система оповещения волонтеров и администраторов (Notification Service)
volunteer_notification_event_v1 и отправлять уведомления, на полученный в сообщении контактный телефон или email.
Модель сообщения NotificationEventV1:
{
"type": "record",
"name": "NotificationEventV1",
"namespace": "ru.cloudjava.rescue.notification.avro",
"doc": "Событие для отправки уведомлений волонтёрам/администраторам",
"fields": [
{ "name": "event_id", "type": { "type": "string", "logicalType": "uuid" } },
{ "name": "occurred_at", "type": { "type": "long", "logicalType": "timestamp-millis" } },
{ "name": "producer", "type": "string" },
{ "name": "incident_id", "type": { "type": "string", "logicalType": "uuid" } },
{ "name": "incident_status",
"type": { "type": "enum", "name": "IncidentStatus", "symbols": ["IN_PROGRESS","SUCCESS","FAIL"] }
},
{"name": "params",
"type": {
"type": "array",
"items": {
"type": "record",
"name": "NotificationEventParamV1",
"fields": [
{
"name": "param_type",
"type": {
"type": "enum",
"name": "ParamType",
"symbols": [
"DESCRIPTION",
"LAT",
"LON",
"LOCATION",
"PERSON_NAME",
"PHOTO_URL",
"PERSON_AGE",
"IDENTIFYING_MARKS",
"LAST_SEEN_CLOTHES",
"LAST_SEEN_DATE"
]
}
},
{ "name": "param_value", "type": "string" }
]
}
}
},
{ "name": "contacts",
"type": {
"type": "array",
"items": {
"type": "record",
"name": "Contact",
"fields": [
{ "name": "contact_type",
"type": { "type": "enum", "name": "ContactType", "symbols": ["EMAIL","PHONE"] }
},
{ "name": "contact", "type": "string" },
{ "name": "volunteer_id", "type": { "type": "string", "logicalType": "uuid" } }
]
}
}
}
]
}at_least_once, то
есть
события могут вычитываться повторно. Требуется реализовать функционал таким образом, чтобы минимизировать или вообще свести к нулю повторные отправки. Добиться этого можно разными
путями:
как настройкой гарантии exactly_once в Кафка (сложный и далеко не всегда нужный путь), так и в коде приложения, вычитывающего сообщения (гораздо более легкий и зачастую
более
производительный путь).
Если у волонтера есть и email и телефон, то уведомление отправляется на оба контакта.
Параметры сообщения для инцидента в статусе IN_PROGRESS:
- Заголовок: "Уважаемый волонтер. Просьба принять участие в поиске пропавшего человека
PERSON_NAMEв городеLOCATION" - Тело сообщения (описан состав параметров тела сообщения. Сами формулировки могут быть в произвольной форме):
- Если контакт
EMAIL, передается вся информация об инциденте:Описание происшествия: DESCRIPTION. Координаты происшествия. Широта: LAT. Долгота: LON. Место происшествия: LOCATION. ФИО пропавшего: PERSON_NAME. Ссылка на фото пропавшего: PHOTO_URL. Возраст пропавшего: PERSON_AGE. Особые приметы пропавшего: IDENTIFYING_MARKS. Одежда, в которой последний раз видели пропавшего: LAST_SEEN_CLOTHES. Дата, когда последний раз видели пропавшего: LAST_SEEN_DATE. - Если контакт
PHONEи отсутствуетEMAIL, то передается полная информация, иначе:
"Подробная информация о пропавшем человеке отправлена вам на почту."
- Если контакт
SUCCESS:
- Заголовок: "Уважаемый волонтер. Поиск пропавшего человека
PERSON_NAMEпрекращен." - Тело сообщения:
"Ура! Мы смогли найтиPERSON_NAMEживым и здоровым! Спасибо за участие в поиске!"
FAIL:
- Заголовок: "Уважаемый волонтер. Поиск пропавшего человека
PERSON_NAMEпрекращен." - Тело сообщения:
"К сожалению, нам не удалось найтиPERSON_NAMEживым и здоровым. Дальнейший поиск не имеет смысла. Спасибо за участие в поиске!"
5. Система управления инцидентами (Incident Service)
- Администраторы должны иметь возможность зарегистрировать инцидент:
POST/api/v1/incident/create- С помощью ключа идемпотентности, передаваемого в заголовке
X-Idempotency-Key, необходимо обеспечить, чтобы при многочисленных запросах на создание одного и того же инцидента, в БД сохранялась только одна запись, а остальные запросы отклонялись с 409 ошибкой. - В запросе передается информация о пропавшем человеке:
- ФИО
- Пол
- Возраст
- Особые приметы
- В чем был одет
- Фотография (ссылка на фото)
- Дата, когда человека видели в последний раз
- Координаты, где человека видели в последний раз (передается точка в виде
lat,lon) - Название населенного пункта, где человека видели в последний раз
- Название района населенного пункта, где человека видели в последний раз.
- Поведение системы при регистрации инцидента:
- Система должна сохранить данные об инциденте, статус инцидента
IN_PROGRESS. Если в БД системы нет населенного пункта или района населенного пункта, то система добавляет соответствующие записи в БД. - Система должна определить идентификаторы и координаты ближайших к инциденту волонтеров (количество волонтеров определяется в настройке, поиск координат происходит по запросу в Tracking Service).
- Система должна запросить контактную информацию о найденных волонтерах в Volunteer Service
- Система должна отправить в топик
volunteer_notification_event_v1событие с необходимой для отправки уведомления информацией о волонтерах. Параметры сообщения:"DESCRIPTION", "LAT", "LON", "DATE", "LOCATION", "PERSON_NAME", "PHOTO_URL", "PERSON_AGE", "IDENTIFYING_MARKS", "LAST_SEEN_CLOTHES", "LAST_SEEN_DATE" - Система должна сохранить знание о том, каким волонтерам предложено участвовать в поиске пропавшего человека.
- Система должна вернуть список идентификаторов и координат выбранных волонтеров в ответ на запрос о регистрации задачи, а также назначенный инциденту идентификатор.
- Требуется обеспечить, чтобы в границы транзакции в БД не входили сетевые запросы получения данных в смежных микросервисах и отправка событий в Кафку.
- Отправка сообщения в Кафку должна быть реализована с помощью паттерна Transactional_Outbox.
- Система должна сохранить данные об инциденте, статус инцидента
- Система должна вычитывать сообщения из топика Kafka
volunteer_incident_assign_event_v1и сохранять информацию о волонтерах, которые приняли заявку на участие в поиске пропавшего человека. Требуется учесть, что сообщения могут приходить повторно (гарантия at least once) а также в редких случаях возможно переупорядочивание сообщений. - Администраторы должны иметь возможность обновить статус инцидента (статусная модель:
IN_PROGRESS,SUCCESS,FAIL), обновить можно статус наSUCCESS,FAIL.PATCH/api/v1/incident/status- В теле запроса передается новый статус и идентификатор инцидента
- Поведение системы при получении статусов
SUCCESS,FAIL- Система обновляет статус инцидента в БД.
- Система получает контактную информацию волонтеров, учавствующих в поиске (запрос в Volunteer Service)
- Система отправляет в топик
volunteer_notification_event_v1событие с соответствующей информацией по инциденту. Параметры сообщения:PERSON_NAME - Отправка сообщения в Кафку должна быть реализована с помощью паттерна Transactional Outbox.
- Требуется обеспечить, чтобы в границы транзакции в БД не входили сетевые запросы получения данных в смежных микросервисах и отправка событий в Кафку.
- Администраторы должны иметь возможность получить всю информацию об инциденте и о принимающих участие в поиске волонтерах
GET/api/v1/incident/{id}- В ответе должна быть следующая информация:
- Идентификатор инцидента
- Информация о пропавшем человеке
- Дата, когда человека видели в последний раз
- Координаты, где человека видели в последний раз (передается точка в виде
lat,lon) - Название района населенного пункта, где человека видели в последний раз
- Статус инцидента
- Список идентификаторов волонтеров, участвующих в поиске, и их текущих координат (при наличии)
- Администраторы должны иметь возможность получить информацию об инцидентах:
POST/api/v1/incident/list- В теле запроса передаются фильтры, по которым необходимо отфильтровать список инцидентов, а также информация о пагинации списка инцидентов (страница, количество записей
на
странице):
- Населенный пункт
- Район населенного пункта
- Год инцидента
- Месяц инцидента
- Статус инцидента
pageFromcount
- Система должна вычитывать сообщения из топика Кафка
volunteer_location_change_event_v1и обновлять координаты волонтера в своей БД, если его идентификатор есть в БД. - Волонтер должен иметь возможность получить постраничный список инцидентов, в которых он принимал участие:
POST/api/v1/incident/volunteer/list- В теле запроса передается:
- идентификатор волонтера
pageFromcount
- Волонтер должен иметь возможность получить постраничный список инцидентов, в которых ему предлагается принять участие, но он еще не ответил согласием или отказом. После того,
как
волонтер отказывается или соглашается принять участие в инциденте, данный инцидент исключается из этого списка:
POST/api/v1/incident/volunteer/pending/list- В теле запроса передается:
- идентификатор волонтера
pageFromcount
Примерная модель данных
В реализации требуется учесть, что связь между волонтером и инцидентом many-to-many.
Также потребуются дополнительные поля для обеспечения идемпотентности записи об инциденте и служебные таблицы, для обеспечения гарантированной отправки сообщения в Kafka.
Incident
idUUID primary keydescriptiontext not nullclosest_latdouble precision not nullclosest_londouble precision not nullcreate_datetimestamptzupdate_datetimestamptzstatustext not null defaultIN_PROGRESS(IN_PROGRESS,SUCCESS,FAIL)location_idreferences location(id)
LostPerson
idUUID primary keyfirst_nametext not nulllast_nametext not nullmiddle_nametextphoto_urltextageintegeridentifying_markstextlast_seen_clothestextlast_seen_datetimestamptz not nullincident_idUUID not null references incident(id)
Location
idUUID primary keynametext not null uniqueparent_loc_idUUID references location(id)create_datetimestamptz not null default nowlocation_kindtext not null default 'PARENT' ('CHILD')update_datetimestamptz
Assigned_Volunteer
idUUID primary key not nullvolunteer_idUUID not nullassign_datetimestamptz not nulllast_known_latdouble precisionlast_known_londouble precisionincident_idUUID not null references incident(id)
6. Нефункциональные требования
- Поддержка
rate_limitingна уровне Gateway Server - В логах номера телефонов и
emailдолжны маскироваться следующим образом:email:someemail@service.com-->s***l@service.com- телефон:
79999999999-->7999***9999
- В Prometheus должны быть следующие метрики помимо стандартных:
incident_count_total(количество инцидентов в регионе): меткаregion, значение — название населенного пункта (или района населенного пункта)incident_result_total: меткаstatus, значение —successилиfailв зависимости от достигнутого результата поиска.
- При организации межсервисного взаимодействия если в результате идемпотентного запроса получена сетевая ошибка или 500 ответ от сервиса, то запрос должен быть повторен указаное в конфигурации сервиса количество раз с экспоненциальной или фиксированной задержкой в зависимости от сценария взаимодействия.
- При организации межсервисного взаимодействия необходимо реализовать паттерн Circuit Breaker
- Зависимые от окружения (
dev,qa,prod) конфигурации должны попадать в сервисы с помощью переменных окружения - Необходимо использовать Spring Boot версии не ниже 3.5.3
- Сервисы должны быть покрыты Unit и интеграционными тестами.
- Для организации хранения данных в БД необходимо использовать механизм миграций Flyway или Liquibase.
- Все даты должны храниться в БД в зоне UTC.
- При работе с БД необходимо использовать время сервера приложения, а не время сервера БД.
- При развертывании в Kubernetes передача логинов и паролей от БД и других систем должна осуществляться с помощью абстракции Secret. Задание со звездочкой (необязательно к реализации) — настроить систему хранения секретов Vault и передавать секреты в приложение с помощью SideCar контейнера vault-agent, описывая секреты в аннотациях Deployment приложения.
- При реализации слоя данных разрешено пользоваться технологиями Spring Data JPA (Hibernate), Spring Data JDBC, Spring Data R2DBC.
- При организации асинхронного взаимодействия через брокер сообщений Apache Kafka сообщения должны быть в формате Avro.
- Устаревшие и более ненужные в БД данные должны очищаться автоматически самим приложением.
7. Запуск автотестов
Для тестирования системы подготовлен набор автотестов. Рекомендуется внимательно изучить тесты каждого микросервиса, чтобы понять ожидаемое поведение в различных сценариях как успешных, так и неуспешных. Разобравшись в том, что ожидается в тесте, вы ответите на большинство вопросов, которые у вас могут возникнуть по ходу реализации.
Если ваш проект разворачивается в кластере Kubernetes на локальном хосте с помощью Minikube, необходимо выполнить следующие шаги, чтобы запустить автотесты:
- Добавить в конфигурацию Kafka advertised listener на
localhost:9093. Для этого требуется:- Добавить протокол безопасности для него в переменную окружения
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT,PLAINTEXT_TEST:PLAINTEXT
ТутPLAINTEXT_TEST:PLAINTEXTиспользуется для тестов - Добавить тестовый листенер в переменную окружения
KAFKA_LISTENERS
KAFKA_LISTENERS: PLAINTEXT://:9092,CONTROLLER://:29093,PLAINTEXT_TEST://:9093 - Добавить тестовый листенер в переменную окружения
KAFKA_ADVERTISED_LISTENERS
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-0.kafka.default.svc.cluster.local:9092,PLAINTEXT_TEST://localhost:9093
- Добавить протокол безопасности для него в переменную окружения
- Запустить все приложения и инфраструктурные компоненты
- Прокинуть порты на
localhostдля Kafka, Postgres и Schema Registry:kubectl port-forward kafka-0 9093kubectl port-forward postgres-0 15432kubectl port-forward SCHEMA_REGISTRY_POD_NAME 8081— требуется заменитьSCHEMA_REGISTRY_POD_NAMEна название поды с Schema Registry
- Запустить туннель для вашего кластера minikube tunnel -p YOUR_CLUSTER_NAME
- Не забудьте добавить в
/etc/hostsмаппинги (сами хосты можете выбрать другие, важно, чтобы все было настроено консистентно) по аналогии с тем как это было сделано в курсе по Cloud Java K8S.127.0.0.1 keycloak.rescue-service.ru 127.0.0.1 grafana.rescue-service.ru 127.0.0.1 prometheus.rescue-service.ru 127.0.0.1 rescue-service.ru - Не забудьте поправить coreDns, чтобы запросы к Keycloak были корректны как извне кластера, так и изнутри.
- Обязательно прочитайте
Readme.mdв проекте с автотестами и обновите конфигурацию вapplication.ymlсогласно рекомендациям, если это требуется.
8. Схемы OpenApi
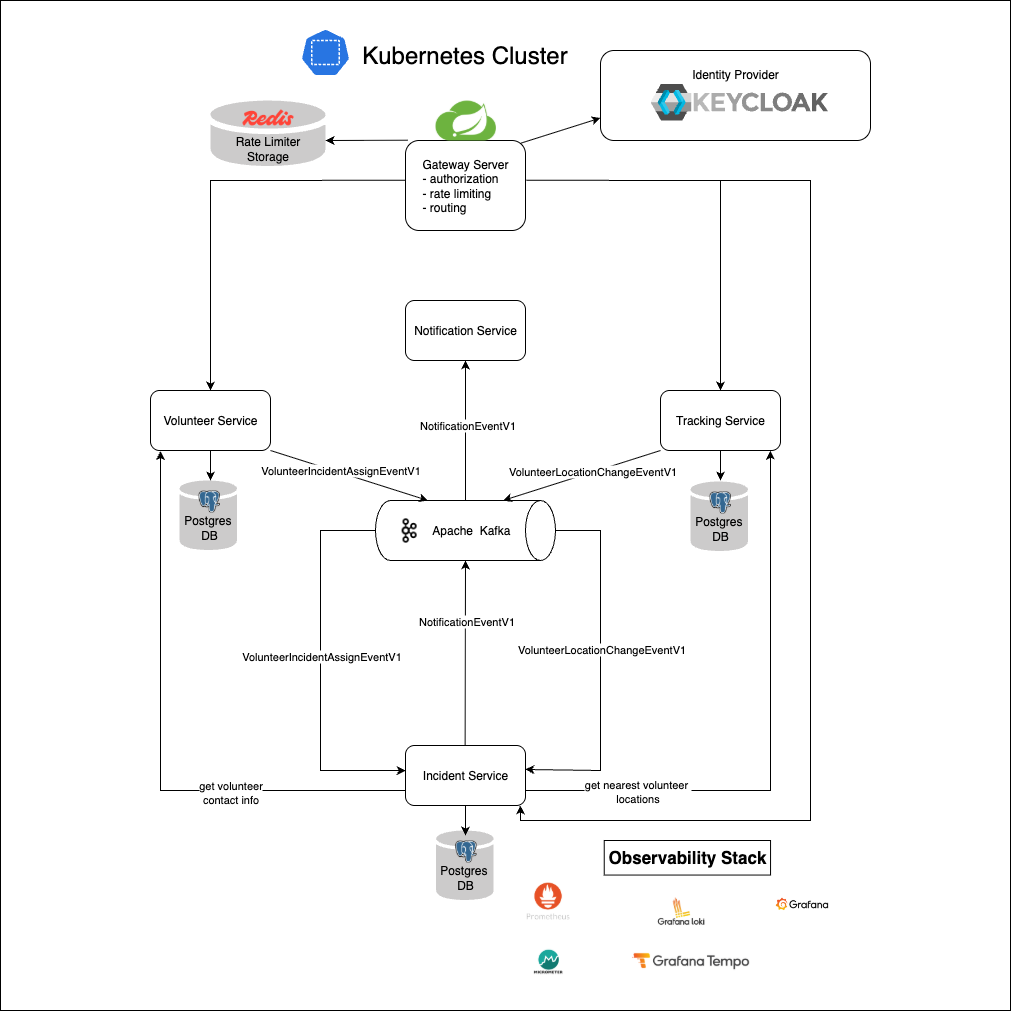
9. Предлагаемая архитектура проекта:
10. Рекомендации по реализации
У вас есть возможность получить доступ к референсной реализации проекта, однако максимальную пользу от выполнения задания вы получите, если выполните его самостоятельно. При этом, рекомендуется следующий подход:
- Определитесь со стеком технологий для конкретного микросервиса: нужен ли в нем Spring Data JPA или возможно легче будет работать с Spring Data JDBC, требуется ли подключение к Kafka, какие зависимости нужны для организации Monitoring, Observability, Tracing и Logging и т.п.
- Декомпозируйте задачу на подзадачи. В рамках ТЗ уже определена декомпозиция по микросервисам и эндпоинтам. Вам требуется декомпозировать реализацию каждого отдельного
эндпоинта. Можно пойти различными путями, например:
- API -> сервисный слой -> слой данных
- Слой данных -> сервисный слой -> API
- При реализации старайтесь распределять задачи таким образом, чтобы планировать их реализацию в рамках двухнедельных спринтов, как это зачастую бывает в крупных компаниях.
- Каждую задачу выполняйте в отдельной feature ветке, после выполнения задачи готовьте Pull Request в ветку
developи проводите ревью своего решения. Старайтесь критично подходить к ревью — обращайте внимание на соответствие решения техническому заданию, на наличие возможных ошибок (особенно часто упускают из вида NPE), стиль кода (рекомендуется придерживаться одного стиля в рамках всего проекта), распределение классов по пакетам, следование принципам SOLID, покрытие тестами и т.п. Pull Request не стоит мержить, если в нем отсутствуют тесты нового функционала. После мержа Pull Request-а, удаляйте более ненужную feature-ветку, чтобы не засорять проект. - В конце каждого двухнедельного спринта подводите итог того, что уже сделано и планируйте задачи на следующий спринт.
- При реализации конкретного эндпоинта внимательно изучите тесты на него из проекта с автотестами. Вероятнее всего вы найдете ответы на большинство вопросов.
- Если вы столкнулись с трудностью реализации, не опускайте руки. Сформулируйте свой вопрос — зачастую в процессе формулирования вопроса находится и ответ на него. Обязательно гуглите и старайтесь найти решение самостоятельно. Если вы задаете вопрос ИИ, учитывайте, что он очень часто дает неверные советы, поэтому обязательно читайте официальную документацию и исходный код, так вы сможете «довести до ума» предлагаемое ИИ решение. Если в результате поиска решения вы ни к чему не пришли, то задайте вопрос в чат поддержки, вам обязательно помогут. При этом четко опишите проблему и как вы пытались ее решить. Рассматривайте обращение в чат как обращение к тим-лиду, который поставил вам задачу на реализацию. Другими словами, не стоит приходить с вопросом — «Как реализовать такой-то функционал, что-то я не разобрался?»
- Когда вся система будет готова, обязательно прогоните автотесты. Если они проходят успешно, значит вы справились с заданием. Если же возникают ошибки, то не спешите расстраиваться — с первого раза выполнить такую сложную работу практически невозможно. Внимательно изучите ошибку, прочитайте логи каждого задействованного в процессе микросервиса, локализуйте проблему и вы найдете ее решение. Такого рода исправления стоит делать так же в отдельных bugfix ветках с Pull Request-ами и код ревью. На каждую найденную ошибку заводите свой bugfix. Не исправляйте все в одном Pull Request-е. Так будет проще отслеживать историю изменения проекта. Логику тестов можно интегрировать в код конкретного микросервиса, чтобы проверить его в изоляции. Однако в этом случае придется мокировать ответы от смежных микросервисов, для этого рекомендуется использовать WireMock.
- Стоит отметить, что проект достаточно сложный как с технической, так и с бизнесовой точки зрения. Вам зачастую придется искать компромиссные решения. Если вы видите несколько возможных вариантов решения той или иной задачи и хотите опробовать их все, то заносите их под feature-toggles, а по умолчанию включайте тот, который считаете наиболее подходящим.
11 Референсная реализация
В референсной реализации для вас подготовлены следующие проекты:
- volunteer-service
- tracking-service
- incident-service
- notification-service
- volunteer-gateway-service
- rescue-service-k8s
Также подготовлено 2 варианта деплоя микросервисов:
- Docker: в каждом микросервисе есть свой
docker-compose.ymlфайл, в котором определен необходимый для запуска этого микросервиса набор компонентов. Вvolunteer-gateway-serviceопределена окончательная конфигурация для деплоя в Docker. - Kubernetes (отдельный проект
rescue-service-k8s)
Для локального запуска с деплоем в Kubernetes вам необходимо:
- Опубликовать все микросервисы в своем Github-репозитории.
- Запустить Github Actions в вашем репозитории: сейчас настройки такие, что Github Actions запускаются при Pull Request-е в ветку
developилиpushв веткуk8s. - В helm-чарты добавить чарт с вашим секретом для скачивания образов. Секрет надо назвать
github-registryпо аналогии с тем, как делали в курсе по k8s. - В helm-чартах микросервисов поменять в
values.yamlссылку на образ из вашего репозитория. - Прописать в
/etc/hostsнужные урлы по аналогии с тем как делали в курсе по k8s:127.0.0.1 keycloak.rescue-service.ru 127.0.0.1 grafana.rescue-service.ru 127.0.0.1 prometheus.rescue-service.ru 127.0.0.1 rescue-service.ru - Настроить свой локальный кластер Minikube по аналогии с тем, как делали в курсе по k8s:
- выделить ресурсы
- добавить
addon ingress - пофиксить coreDns, чтобы запросы к Keycloak проходили как изнутри кластера, так и снаружи
- После запуска и настройки кластера, надо перейти в репозиторий
rescue-service-k8sв директориюhelmи выполнить командуhelmfile apply(еслиhelmfileне стоит, то установите его с официального сайта или вручную установить каждый релиз. - Также необходимо запустить туннель Minikube и выполнить
port-forwardдля Kafka, Postgres, Schema Registry.
После этого можно запускать тесты.