Вводная часть
Назначение и задачи проекта
Для начала определимся с отправной точкой в этом, надеюсь, увлекательном путешествии в мир Spring Cloud и микросервисов. Итак, мы выступаем в роли команды, которая пишет бэкенд для сервиса заказов еды на вынос.
За нами закреплена реализация следующих задач:
- управление меню нашего онлайн-кафе
- регистрация, аутентификация и авторизация клиентов и сотрудников кафе
- управление заказами зарегистрированных пользователей
- организация возможности пользователям оставить отзыв о блюде
- предоставление фронтенду информации о блюдах и пользовательских отзывах
- максимально независим от остальных
- легко масштабировался горизонтально за счет поднятия новых инстансов сервиса
- имел возможность изменять конфигурацию без перезапуска сервиса
- был устойчив к возможным сбоям
- предоставлял возможность отслеживать свое текущее состояние
Манифест от Heroku “12-факторное приложение”
- Одна кодовая база - одно приложение. Если несколько приложений используют общий код, то его можно выделить в отдельную библиотеку, и объявить ее как зависимость. В программировании применяется принцип DRY (Don’t Repeat Yourself), однако при проектировании микросервисов разработчикам иногда целесообразно отходить от этого правила в части касающейся моделей состояния, передаваемых по сети или Data Transfer Objects (DTOs) - они адаптируются под каждый микросервис, и в некоторых случаях могут быть полностью идентичными, в некоторых - нет. В библиотеку обычно выносится бизнес-логика, а не DTOs.
- Явное объявление и изолирование зависимостей. Приложение не должно зависеть от неявно существующих и доступных системе пакетов. Java
разработчики для
управлением зависимостями в большинстве случаев используют Maven или Gradle, где явно прописывают все необходимое для запуска и корректной работы своего
приложения. Под неявными зависимостями подразумевается, например, не прописанная в манифесте зависимостей (build.gradle или pom.xml)
утилита
curl, по каким-либо причинам необходимая для работы приложения: на машине разработчика она может присутствовать, но в среде выполнения - нет. - Разделение конфигурации приложения и кода. Иногда приложения хранят конфигурацию как константы в коде. Это нарушение методологии двенадцати факторов, которая требует строгого разделения конфигурации и кода. Конфигурация может существенно различаться между развёртываниями, код не должен различаться. При этом такие конфигурационные параметры, как логины, пароли, адреса БД, ключи API сторонних сервисов и т.п. рекомендуется хранить в переменных окружения, а не в конфигурационных файлах. Переменные окружения также считаются частью конфигурации приложения, их легко изменить между развёртываниями, не изменяя код, они являются независимым от языка и операционной системы стандартом, они не публикуются в репозиторий. Проверить правильность соблюдения этого пункта можно так: оцените, можете ли вы опубликовать свой код в открытый доступ без компрометации персональных учетных данных.
- Сторонние службы (базы данных, кэши и т.д.) рассматриваются как подключаемые ресурсы, данные для подключения которых должны храниться в
конфигурации.
При разработке нашего приложения данные для подключения к сторонним службам в dev-среде для простоты мы будем хранить в конфигурационных файлах,
а для prod-среды конфигурационные файлы будут ссылаться на переменные окружения. Например:
spring.datasource.username=${DB_USERNAME} - Строгое разделение стадий сборки, релиза и выполнения.
Согласно методологии двенадцати факторов приложение проходит несколько этапов жизненного цикла:
- Сборка - преобразование кода в исполняемый пакет (сборку), включая загрузку зависимостей, компиляцию файлов и ресурсов. Сборка инициируется разработчиком приложения всякий раз, когда разворачивается новый код. Тесты, которые пишет разработчик, входят в стадию сборки.
- Релиз - объединение полученной на предыдущем этапе сборки с конфигурацией для конкретной среды исполнения. Полученный релиз содержит сборку и конфигурацию и готов к немедленному запуску в среде выполнения. Каждый релиз неизменяем и должен иметь уникальный идентификатор, а также храниться в центральном репозитории. Если говорить о тестовом стенде, то для него готовится отдельный релиз на основе сборки, то есть собранный проект объединяется с конфигурациями для стенда. На нем может проводится нагрузочное тестирование, интеграционное тестирование уже развернутых микросервисов и т.п.
- Выполнение - запуск собранного релиза в соответствующей ему среде выполнения. Запуск может происходить автоматически в таких случаях, как перезагрузка сервера или перезапуск упавшего процесса менеджером процессов.
- Приложение или запускаемый в рамках него процесс не должны хранить внутри себя состояние. Любые данные, требующие сохранения должны храниться в сторонней службе.
- Приложение должно быть полностью самодостаточным и не должно полагаться на наличие стороннего веб-сервера во время выполнения. В случае со Spring Boot приложениями разработчики из коробки получают по умолчанию Tomcat при использовании блокирующего Spring Web, и Netty при использовании реактивного Spring WebFlux.
- Приложение должно иметь возможность быть запущенным как несколько процессов на различных физических машинах (масштабироваться). Отсутствие хранящихся в памяти приложения и доступных всем процессам разделяемых данных гарантирует, что масштабирование является простой и надежной операцией. Разделяемые данные и общее состояние должны храниться в сторонних службах, например, распределенный кэш Redis.
- Процессы приложения являются утилизируемыми. Это означает, что они могут быть запущены и остановлены в любой момент. При этом время запуска процесса должно стремиться к минимуму, а его завершение должно быть корректным - текущие запросы должны быть отработаны, а новые не должны приниматься.
- Необходимо поддерживать различные окружения (dev/staging/prod) максимально похожими. Это подразумевает также использование одинаковых сторонних служб в различных окружениях.
- Логирование должно рассматриваться как поток событий. Приложение никогда не занимается маршрутизацией и хранением своего потока вывода. Приложение не должно записывать логи в файл и управлять файлами логов. Вместо этого каждый выполняющийся процесс записывает без буферизации свой поток событий в стандартный вывод stdout. Это позволяет агрегировать события от разных процессов, включая как процессы приложения, так и сторонние службы.
- Задачи администрирования и управления должны выполняться с помощью разовых процессов и подчиняться тем же правилам, что и регулярные
процессы:
- Они запускаются на уровне релиза, используя те же кодовую базу и конфигурацию, что и любой другой выполняющийся в этом релизе процесс.
- Код администрирования должен поставляться вместе с кодом приложения, чтобы избежать проблем синхронизации.
- Зависимости должны быть объявлены в основном манифесте зависимостей, чтобы процесс мог быть выполнен при обычном развертывании.
- Конфигурация задачи должна находиться в переменных окружения, чтобы ее можно было выполнить в разных окружениях.
Паттерны проектирования микросервисной архитектуры
- Service Discovery - позволяет микросервисам общаться между собой, не зная точных IP адресов инстансов.
- API Gateway - выступает в качестве входной точки в систему микросервисов, маршрутизируя входящие со стороны клиентов запросы. Именно в Gateway логичнее всего реализовывать сквозной функционал: безопасность, ограничение количества входящих запросов, кэширование сессий и т.п.
- Externalized Configuration - обеспечивает возможность разделить кодовую базу и конфигурации микросервисов.
- Distributed Tracing - обеспечивает возможность отслеживания жизненного пути входящего запроса, проходящего через несколько микросервисов.
- Log Aggregation - агрегирует логи от всех микросервисов и перенаправляет их в систему централизованного анализа логов.
- Circuit Breaker - предотвращает каскадное падение сервисов в случае, когда микросервисы используют синхронное взаимодействие между собой (блокирующие запросы) и один из сервисов по какой-либо причине не отвечает в течение длительного периода времени или регулярно возвращает ошибку 5ХХ.
- Transactional Outbox - используется для обеспечения гарантированной записи сообщения в БД и отправки сообщения в брокер сообщений.
Схема и стек приложения
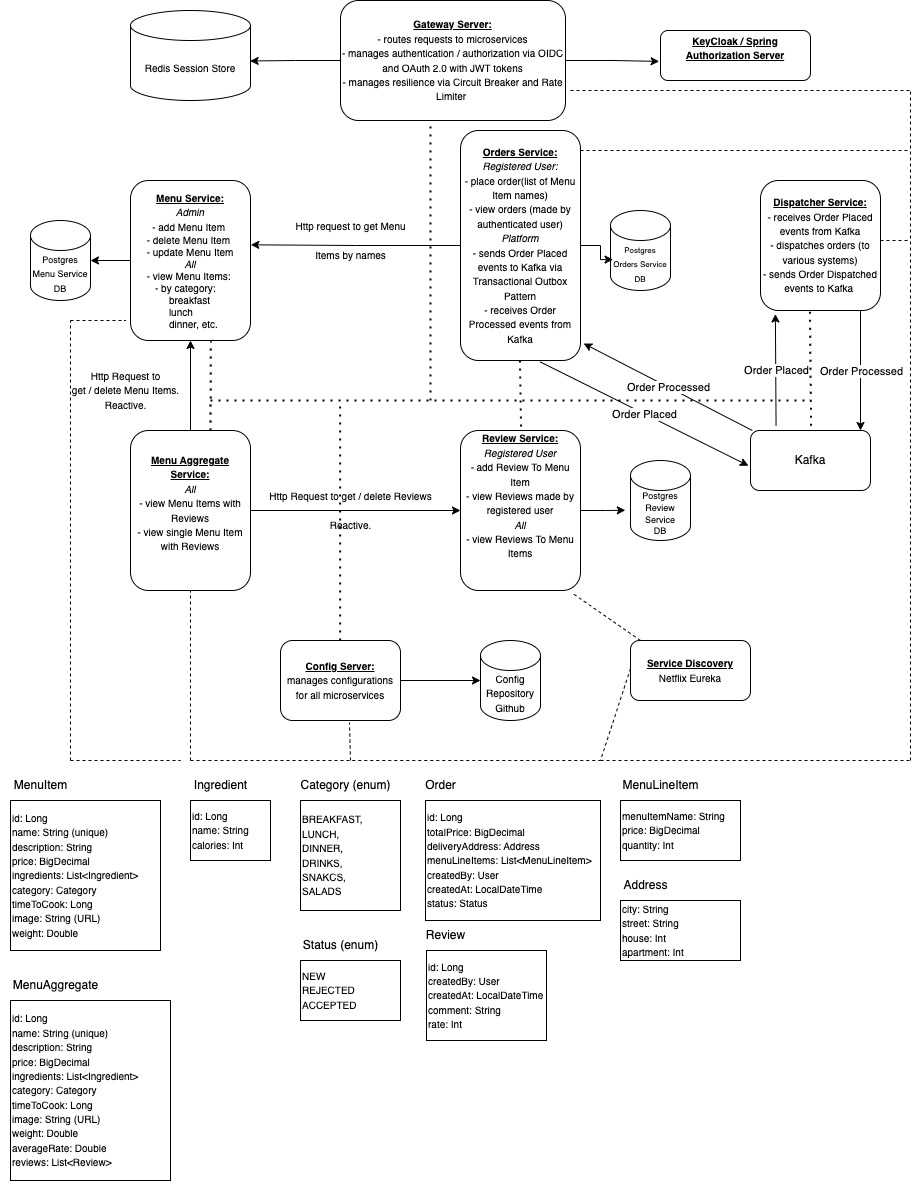
Тим-лид предоставил ряд рекомендаций: использовать
- Spring Boot 3 в качестве основного фреймворка для написания микросервисов
- Spring Cloud Config Server для хранения конфигураций
- Spring Cloud Netflix - Eureka в качестве Service Discovery
- PostgreSQL 16 в качестве баз данных для микросервисов (у каждого микросервиса своя база)
- Spring Cloud Gateway в качестве входной точки в приложение
- Apache Kafka в качестве брокера сообщений для обеспечения асинхронного взаимодействия микросервисов
- Redis для кэширования данных
- Keycloak + OIDC/OAuth2 для аутентификации/авторизации
Назначение и API микросервисов
Основными микросервисами, отвечающими за реализацию бизнес-логики, станут:
- Menu Service
- Orders Service
- Review Service
- Menu Aggregate Service
- Order Dispatch Service
Menu Service
Предоставляет REST API для CRUD-операций с меню:- POST /v1/menu-items - создать блюдо, информация о блюде передается в теле запроса. Доступно для сотрудников, информация о сотруднике передается в токене доступа.
- DELETE /v1/menu-items/{id} - удалить блюдо. Доступно для сотрудников, информация о сотруднике передается в токене доступа
- PATCH /v1/menu-items/{id} - обновить блюдо, параметры обновления передаются в теле запроса. Доступно для сотрудников, информация о сотруднике передается в токене доступа
- GET /v1/menu-items/{id} - получить блюдо. Доступно всем пользователям
- GET /v1/menu-items?category={category}&sort={sort} - получить список блюд из выбранной категории, отсортированный или по алфавиту (AZ, ZA), или по цене (PRICE_ASC, PRICE_DESC), или по дате создания (DATE_ASC, DATE_DESC). Доступно всем пользователям
Orders Service
Предоставляет REST API для создания и просмотра совершенных пользователем заказов:- POST /v1/menu-orders - создать заказ, информация о заказе передается в теле запроса. Доступно для зарегистрированных клиентов онлайн кафе, информация о пользователе передается в токене доступа
- GET /v1/menu-orders?sort={sort}&from={from}&size={size} - получить пагинированный список (используется offset пагинация) заказов пользователя, отсортированный по дате создания (DATE_ASC, DATE_DESC). Информация о пользователе передается в токене доступа.
Отправляет в топик Kafka v1.public.orders_outbox сообщения о создании заказа после того, как заказ был
сохранен.
Для обеспечения гарантированной отправки сообщения применяется паттерн
Transactional
Outbox, для чего используется Kafka Connect
(система, позволяющая надежно вычитывать данные из внешних систем в Kafka и отправлять данные из топиков Kafka во внешние системы) и
Debezium Postgres Connector (опенсорсный коннектор, который
постоянно вычитывает изменения в БД и отправляет их в топики Kafka).
Вычитывает из топика Kafka v1.orders_dispatch сообщения о том, что заказ был обработан и передан на исполнение или отклонен, обновляет статус
заказа в Postgres.
Дополнительно: Kafka Connect на примере Debezium PostgresConnector.
Review Service
Предоставляет REST API для CRUD-операций с отзывами пользователей о блюдах:- POST /v1/reviews - создать отзыв, информация об отзыве передается в теле запроса. Информация о пользователе, создающем отзыв, передается в токене доступа, доступно для зарегистрированных пользователей. Рейтинг блюда должен быть от 1 до 5.
- GET /v1/reviews/{id} - получить отзыв по ID. Доступно всем пользователям
- GET /v1/reviews/my?sortBy={sort}&from={from}&size={size} получить пагинированный список отзывов конкретного пользователя. Список отсортирован по дате создания: DATE_ASC, DATE_DESC. Информация о пользователе передается в токене доступа. (доступно для зарегистрированных пользователей)
- GET /v1/reviews/menu-item/{id}?sort={sort}&from={from}&size={size} - получить пагинированный список отзывов к конкретному блюду. Список отсортирован по дате создания: DATE_ASC, DATE_DESC. Доступно всем пользователям. Также в ответе передается информация о рейтинге и средней оценке блюда.
- POST /v1/reviews/ratings - получить рейтинги и средние оценки блюд, идентификаторы которых передаются в теле запроса. Рейтинг блюда рассчитывается согласно доверительному интервалу биномиального распределения по методу Уилсона (Wilson Score Confidence Interval). За основу взяты материалы из статей How to Build a 5 Star Rating System with Wilson Interval и How Not To Sort By Average Rating.
Menu Aggregate Service
Предоставляет REST API для агрегированных запросов блюд с отзывами или с рейтингами:- GET /v1/menu-aggregate/{menuId}?sort={sort}&from={from}&size={size} - получить информацию о блюде с отзывами. Список отзывов пагинирован и отсортирован по дате создания: DATE_ASC, DATE_DESC.
- GET /v1/menu-aggregate?category={category}&sort={sort} - получить информацию о блюдах из указанной категории. Блюда отсортированы или по алфавиту (AZ, ZA), или по цене (PRICE_ASC, PRICE_DESC), или по дате создания (DATE_ASC, DATE_DESC), или по рейтингу (RATE_ASC, RATE_DESC). Информация по каждому блюду включает в себя рейтинг блюда, полученный из Review Service.
Order Dispatch Service
Реализует обработку заказов-
Вычитывает из топика Kafka
v1.public.orders_outboxсообщения о создании заказа, далее происходит обработка заказа. На текущий момент логика заключается в логировании события. -
После обработки заказа отправляет в топик Kafka
v1.orders_dispatchсообщение об обработке заказа, содержащее статус заказа после обработки.
Работа с проектом и инструменты